
最强AlphaGo横空出世,摆脱人类自学3天,100:0完败“老狗”

人工智能迎来了一个里程碑。
北京时间19日01:00,谷歌人工智能公司DeepMind团队公布了最强版AlphaGo ,代号AlphaGo Zero。
此次的亮点在于,AlphaGo Zero可以彻底摆脱人类的知识“自学成才”,无需人类指导就能让自己成为自己的老师。
当今世界围棋第一人柯洁更是直言,这样的AlphaGo是最强的,对于Alphago的自我进步来讲,人类太多余了。
1,迄今最强AlphaGo:不使用人类知识
今年5月,以3:0的比分赢下中国棋手柯洁后,AlphaGo宣布退役,但DeepMind并没有停下研究的脚步。
今天,在国际学术期刊《自然》(Nature)上发表的一篇研究论文中,Deepmind讲述了新版程序AlphaGo Zero:从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋,并以100:0的战绩击败“前辈”。
DeepMind这篇最新的Nature论文,有一个朴素的标题——《不使用人类知识掌握围棋》。

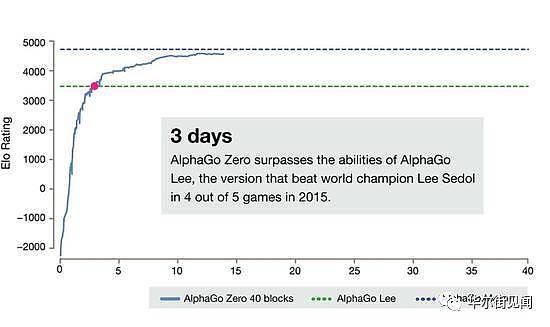
世界顶尖棋手的养成,动辄需要数十年的训练、磨砺。但AlphaGo Zero创造了一个纪录:3天。
仅三天时间,AlphaGo Zero自行掌握了围棋的下法,还发明了更好的棋步。这期间,除了被告知围棋的基本规则,它摆脱了人为的大数据,未获得人类帮助或人类棋谱。

AlphaGo Zero学到的围棋知识(图片来源:DeepMind 论文)
经过短短3天的自我训练,AlphaGo Zero就强势打败了此前战胜李世石的旧版AlphaGo,战绩是100:0的。
经过21天的自我训练,AlphaGo Zero又达到了AlphaGo Master的水平。
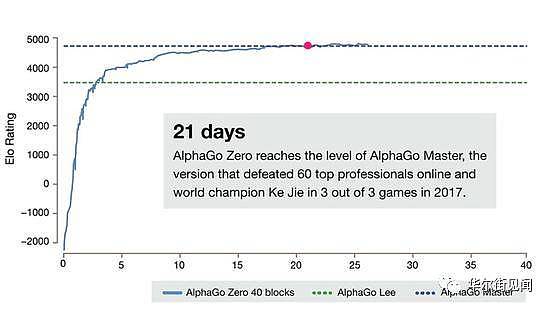
“Master”曾击败过世界顶尖的围棋选手,甚至包括世界排名第一的柯洁。

仅仅40天后,AlphaGo Zero已经可以在与所有其它版本的AlphaGo对弈中获得90%的胜率了。
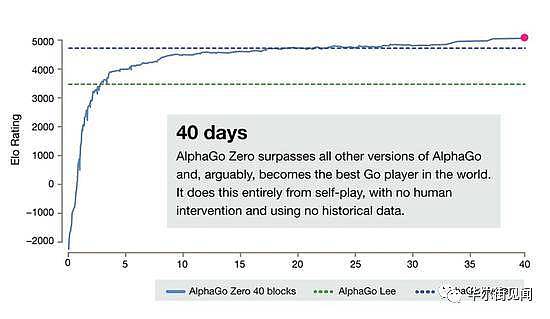
AlphaGo的首席研究员大卫·席尔瓦(David Silver)表示,“由于未引入人类棋手的数据,AlphaGo Zero远比过去的版本强大,我们去除了人类知识的限制,它能够自己创造知识。”
2,AlphaGo Zero非常“低碳”,只用4个TPU
值得一提的是,AlphaGo Zero还非常“低碳”,只用到了一台机器和4个TPU(谷歌专为加速深层神经网络运算能力而研发的芯片),极大地节省了资源。
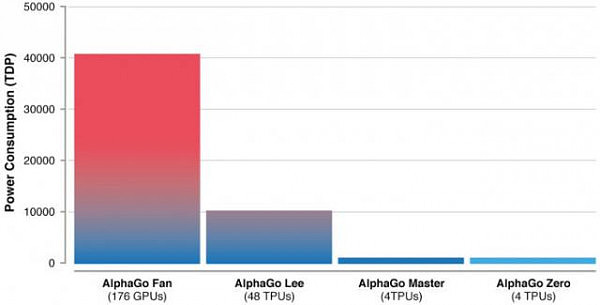
AlphaGo此前的版本,在战胜人类围棋职业高手之前,它经过了好几个月的训练,依靠的是多台机器和48个TPU。
据介绍,AlphaGo Zero采用了新的强化学习方法,从一个不知道围棋游戏规则的神经网络开始,然后通过将这个神经网络与强大的搜索算法结合,然后就可以实现自我对弈了。在这样的训练过程中,神经网络被更新和调整,并用于预测下一步落子和最终的输赢。
这一更新后的神经网络将再度与搜索算法组合,这一过程将不断重复,创建出一个新的、更强大版本的AlphaGo Zero。在每次迭代中,系统的性能和自我对弈的质量均能够有部分提高。
所谓“日拱一卒,功不唐捐”,最终的神经网络越来越精确,AlphaGo Zero也变得更强,在功耗上也更为高效。
3,围棋只是开始,AlphaGo Zero的未来
此次AlphaGo Zero的出现不仅仅意味着围棋上的成功,这一进展标志着通用型AI发展的大一里程碑。
除了下棋赢过人类,通用型AI能做更多事情。由于AlphaGo Zero能够从一无所知实现自学成才,如今其天赋可以在诸多现实问题上派上用场。
目前深度学习需要大量数据,而数据的获得成本高昂且难度十分大,有了这项技术后,人类今后将有可能解决更大的挑战,给人类生活带来根本性的变化。
DeepMind首席执行官Demis Hassabis承认,已运用这个技术解决实际生活中的许多问题。范围可以包括预测蛋白质分子的形状,有望成为药物发明的一大突破;还可以设计新材料和进行气候建模。
Hassabis认为,在接下来十年,AlphaGo的迭代产品将成为科学家和医学专家,与人类并肩工作,这将会有可能对我们的生活产生根本性的影响。


 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


